clsTesseractGetText Step
Description:
This step uses the optical character recognition “OCR” feature with Google’s Tesseract engine and gets the text from the image provided.
Inputs
- imageFilePath – file path to the image file
- selLanguage – select the character recognition language
- selRegionName – select region name
- textVarGlobal – variable or global to hold the recognized text
- percentVarGlobal – Variable or global hold the recognition percent
Returns
- True – step executed successfully
- False – step failed to execute
Usage:
Example:
Let’s build and execute the “clsTesseractGetTextStepDef” example.
- Create a new process definition called “clsTesseractGetTextStepDef”
- Select the definition and click the “design” button
- Drag a "clsTesserActGetText" step from the toolbox
- Connect the dots between the start and “clsTesserActGetText” step
- Define a variable/global to store the result after execution
- Click the "clsTesserActGetText" step to configure its "Settings" properties. Provide a name to the step. Provide the image file path on the app server. Select the language from the dropdown list. Provide the variable/global to store the result after execution.

- Click on the "clsTesserActGetText" step to configure its "Advanced" properties. Select the image region name from the dropdown list. Provide the variable/global to hold the image recognition percent.
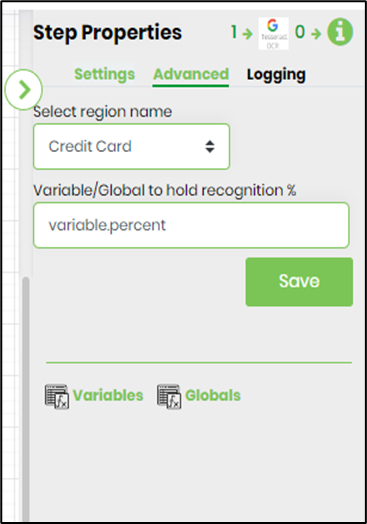
- Save the process definition. Create a new process instance and execute. The process step should recognize the text the barcode image represents and store the translation in the variable.text as configured. The variable.percent holds the recognition %
Configuration:
FlowWright ships with language files for English by default. Select the following menu option to configure other languages for optical character recognition.

The Tesseract OCR Language Configuration is rendered on a new page as below. Please select the desired languages and click the button to configure them.

Definition Sample:
You may download the sample definition(s) from the link here and later import it (drag-drop) to your FlowWright Process Definition (XML file) or Form Definition (HTML file) page.
NOTE: Please verify and complete the process steps for any missing configurations, such as file path references and database connections after import. Then, save the definition to confirm the changes.
Click here to download the sample file.